Dein Analytics-Dashboard lügt dich an – und du hast es selbst so gebaut
Wir haben ca. 775.000 AI-Responses von 25 Brands, 8 Märkten und 8 AI-Modellen über einen Zeitraum von 30 Tagen analysiert. Die Insights sollten jedem CMO schlaflose Nächte bereiten.
Wir haben ca. 775.000 KI-Antworten von 25 Brands, 8 Märkten und 8 KI-Modellen über einen Zeitraum von 30 Tagen analysiert. Was wir herausgefunden haben, dürfte jedem CMO schlaflose Nächte bereiten.
Die Bedrohung ist nicht die Neuartigkeit von KI. Es ist die Tatsache, dass die Lücke zwischen Ihrem Analytics-Dashboard und Ihrer tatsächlichen Brand-Sichtbarkeit in der KI riesig, strukturell und immer größer wird – und die meisten Marketingorganisationen sind völlig blind dafür.
Historisch gesehen waren Klicks nie ein echter Maßstab für den Markenwert. Sie haben die Reibung gemessen; wie oft ein User Google verlassen musste, um eine Antwort zu finden. KI beseitigt diese Reibung. Wenn ein User ein LLM fragt, welche Bank er wählen, welche Software er kaufen oder welcher Brand er vertrauen soll, erhält er eine selbstbewusste, konkrete Antwort.
Ihre Brand ist entweder in dieser Antwort enthalten oder nicht. Und in beiden Fällen zeichnet Ihr Google Analytics absolut nichts auf.
Das Dashboard funktioniert nicht fehlerhaft. Es wurde einfach für eine Welt gebaut, die still und heimlich ersetzt wird.
Was uns ca. 775.000 KI-Antworten gezeigt haben:
Mentions vs. Recommendations: Der KI-Sentiment-Blindspot Eine Brand-Erwähnung (Mention) und eine positive Empfehlung (Recommendation) sind grundlegend verschieden. In unserem gesamten Datensatz reicht die Lücke zwischen roher KI-Sichtbarkeit und positivem Sentiment von 19 % bis 95 %. Dies schafft einen massiven Blindspot: Die meisten Brands haben keine Ahnung, ob KI sie als Leader oder als warnendes Beispiel darstellt.
Kein Longtail: Challenger-Brands verschwinden in der KI Die KI-Suche ist eine Winner-Take-All-Arena. Sie bevorzugt Category Leaders stark und löscht die „Longtail“-Keywords, auf die Challenger-Brands im Wettbewerb angewiesen sind, praktisch aus. Ohne dieses traditionelle SEO-Sicherheitsnetz ist die Realität knallhart: Wenn Sie nicht die Top-Autorität sind, existieren Sie in KI-Antworten nicht.
Die klassische SEO-Falle: In der Suche gewinnen, in der KI verlieren Eine außergewöhnliche organische Suchleistung garantiert keine KI-Sichtbarkeit mehr. Tatsächlich hinkt jede fünfte leistungsstarke Brand bei der KI-Discovery völlig hinterher. Die am stärksten gefährdeten Unternehmen sind diejenigen, die sich in trügerischer Sicherheit wiegen – weil sie die perfekten Dashboards für den Kanal von gestern gebaut haben.
Methodik und Datenquelle
Wir haben die 3RD-Plattform genutzt, um strukturierte Metadaten aus ca. 775.000 KI-Antworten von 25 Brands im April und Mai 2026 zu analysieren. Der Datensatz umfasst 12 Branchen und 8 Märkte mit einer bewussten Gewichtung auf skandinavische Länder und digital hochentwickelte Brands. Die Analyse deckte acht führende KI-Modelle ab: ChatGPT, Gemini, Perplexity, Claude, Mistral, DeepSeek, Grok und Llama.
Für jede KI-Antwort trackt die Plattform drei entscheidende Metriken:
Presence: Ob die Brand erwähnt wurde.
Sentiment: Ob der Tonfall positiv, neutral oder negativ war.
Actionability: Ob die Antwort einen Outbound-Link enthielt.
Ein Hinweis zur Stichprobe: Die 25 analysierten Brands sind keine Zufallsstichprobe; es handelt sich um Organisationen, die ihre KI-Sichtbarkeit bereits aktiv überwachen. Da diese Unternehmen digital fortschrittlicher sind als der Marktdurchschnitt, sind diese Ergebnisse eher richtungsweisend robust als statistisch verallgemeinerbar. Da diese 25 Brands die „digitale Avantgarde“ darstellen, ist es sehr wahrscheinlich, dass die hier identifizierten Sichtbarkeitslücken und Sentiment-Risiken für den breiteren, weniger vorbereiteten Markt noch ausgeprägter sind.
Ergebnis 1: Die Sentiment-Lücke
In unserem Datensatz reicht die Lücke zwischen der Erwähnung einer Brand und ihrer positiven Darstellung in einer KI-Antwort von 19 % bis 95 %. Während beide Metriken auf einem Standard-Monitoring-Dashboard identisch als „Sichtbarkeit“ angezeigt werden, repräsentieren sie völlig unterschiedliche kommerzielle Realitäten.

Die durchschnittliche positive Sentiment-Rate liegt bei etwa 70 % – aber dieser Durchschnitt verschleiert die wahre Geschichte. Die Varianz ist das eigentliche Ergebnis:
Das obere Ende (82–95 %): Brands in den Bereichen Analytics-Software, Enterprise-Tech, Baustoffe, Outdoor-Bekleidung und Recommerce erreichten eine fast vollständig positive Darstellung. Wenn die KI diese Brands erwähnt, setzt sie sie in einen vorteilhaften Kontext und bestätigt sie als Premium- oder bevorzugte Optionen.
Das untere Ende (19–56 %): Brands im Banking, bei Automobil-Marktplätzen, Versicherungen und Immobilien tauchen zwar regelmäßig auf, aber hauptsächlich in neutralen Mentions. Die KI erkennt ihre Existenz an, ohne jedoch positives Brand Equity hinzuzufügen. In diesen Kategorien ist eine neutrale Erwähnung oft eine kommerzielle Sackgasse. Wenn die KI eine Brand ohne positives Sentiment auflistet, nimmt sie lediglich einen Marktteilnehmer wahr, anstatt eine Lösung zu empfehlen, was die Brand praktisch auf den Status eines reinen Commodities reduziert.
Die Ursache: Kategorische Autorität vs. Commoditization
Die Brands, die das positive Sentiment dominieren, haben eines gemeinsam: Sie stehen für ein spezifisches, klares Leistungsversprechen, das KI-Modelle konsistent mit Qualität oder Leadership assoziieren. Wenn eine Brand diesen Raum besetzt, ist fast jede Erwähnung eine positive Empfehlung.
Umgekehrt agieren Brands mit geringem Sentiment in commoditisierten Kategorien, in denen Wettbewerber als austauschbar wahrgenommen werden. Eine Bank ist eine Bank; eine Versicherung ist eine Versicherung. Die KI erwähnt sie alle, behandelt sie aber neutral.
In diesen Kategorien ist eine neutrale Erwähnung oft eine kommerzielle Sackgasse. Wenn die KI eine Brand ohne positives Sentiment auflistet, nimmt sie lediglich einen Marktteilnehmer wahr, anstatt eine Lösung zu empfehlen, was die Brand effektiv auf den Status eines reinen Commodities reduziert.
Hohe Sichtbarkeit ist eine falsche Metrik
Das deutlichste Muster in den Daten widerlegt das Volumen als Erfolgsmetrik: Eine Brand mit geringer KI-Sichtbarkeit (die in weniger als 25 % der Antworten auftaucht) kann eine positive Sentiment-Rate von über 85 % erzielen. In der Zwischenzeit kann eine Brand mit der dreifachen Sichtbarkeit eine positive Sentiment-Rate von unter 50 % verzeichnen.
Wir nennen das die Sentiment-Lücke – die Distanz zwischen der Sichtbarkeit einer Brand und der Häufigkeit, mit der diese Sichtbarkeit positiv besetzt ist. Für manche ist die Lücke vernachlässigbar. Für andere stellt sie eine enorme Menge an KI-Präsenz dar, die Brand Awareness erzeugt, die jedoch völlig frei von positiver Ausrichtung ist.
Ergebnis 2: Das Zwei-Klassen-KI-System
Die KI-gestützte Suche konzentriert ihre Sichtbarkeit auf einige wenige ausgewählte Brands und ignoriert den Rest weitgehend. In jeder analysierten Kategorie hat sich eine strukturelle Kluft aufgetan, die Märkte in zwei unterschiedliche Klassen spaltet – und die meisten Brands haben keine Ahnung, auf welcher Seite sie stehen.
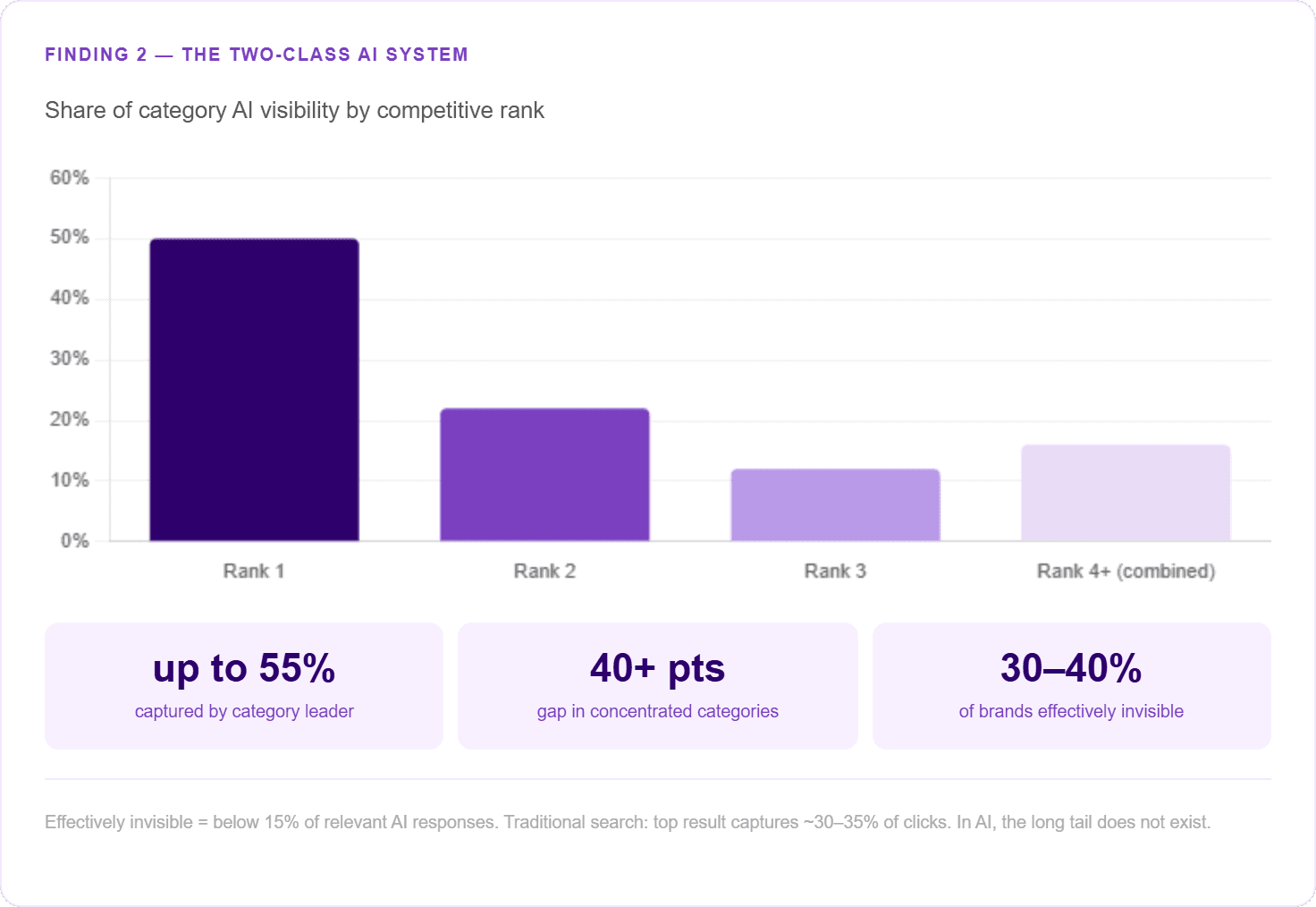
Die Sichtbarkeitslücke zwischen Marktführern und Challengern variiert je nach Kategorie stark. In fragmentierten Märkten wie dem Versicherungswesen beträgt die Lücke nur 1–2 Prozentpunkte. In stark konzentrierten Kategorien kann ein einziger Leader jedoch bis zu 55 % aller KI-Erwähnungen auf sich vereinen und den nächsten Wettbewerber um mehr als 40 Punkte übertreffen.
Der Trend ist klar: Leader haben einen dauerhaften strukturellen Vorteil, und diese Kluft vergrößert sich, je reifer eine Kategorie wird.
Der Tod des Longtails
In der traditionellen Suche erhält das Top-Ergebnis rund 30 % der Klicks, aber die Positionen sechs bis zehn generieren immer noch Traffic. Der Longtail existiert. In der KI wird der „Longtail“ – die sekundäre Sichtbarkeit, die Challenger-Brands am Leben erhält – praktisch ausgelöscht. Während Google Nischen-Discovery ermöglicht, ist die KI-Suche ein Winner-Take-All-Spielfeld, das die Präsenz an der absoluten Spitze konzentriert.
In unserem gesamten Datensatz sind 30 % bis 40 % der etablierten Wettbewerber-Brands praktisch unsichtbar – sie tauchen in weniger als 15 % der relevanten KI-Antworten auf. Das sind keine schwachen Brands; es sind große Marktteilnehmer mit beträchtlichen Budgets und einer starken organischen SEO-Präsenz. Dennoch existieren sie in KI-generierten Antworten schlichtweg nicht.
Der Threshold-Effekt: Antworten vs. Fußnoten
Unsere Daten zeigen einen klaren Threshold-Effekt (Schwellenwerteffekt), der auf Sichtbarkeit und Tonfall basiert:
Unter 15–20 % Sichtbarkeit: Brands werden fast nie positiv dargestellt. Sie werden lediglich neutral als grundlegende Marktteilnehmer aufgelistet.
Über 60 % Sichtbarkeit: Brands überschreiten eine Schwelle, ab der die KI sie konsistent mit positivem Sentiment darstellt.
Dadurch entsteht ein Zwei-Klassen-System: Brands, die die Antwort sind, und Brands, die lediglich eine Fußnote sind.
Das Modell-Dilemma: Durchschnitte verschleiern die Strategie
Erschwerend kommt die Model Divergence hinzu. ChatGPT, Gemini, Perplexity und Claude haben oft grundlegend unterschiedliche, datenbasierte Meinungen darüber, wer eine Kategorie gewinnt.
Ein einzelner, aggregierter KI-Sichtbarkeits-Score mittelt mehrere konkurrierende Wettbewerbsrealitäten zu einer Metrik, die keine davon präzise beschreibt. Wenn Sie Ihrem Führungsteam eine einzige, aggregierte KI-Sichtbarkeitszahl melden, verstecken Sie Ihre kritischsten strategischen Risiken in einem Durchschnitt.
Ergebnis 3: Die klassische SEO-Falle
Dies war unser unerwartetes Ergebnis: Ungefähr jede fünfte Brand in unserem Datensatz kombiniert eine starke organische Suchpräsenz mit einem KI-Sichtbarkeits-Score von unter 40 %. Die Bedrohung für diese leistungsstarken Brands ist nicht ihr SEO-Erfolg, sondern das trügerische Sicherheitsgefühl, das er vermittelt. Da ihre klassischen Dashboards weiterhin Wachstum in einem schrumpfenden Kanal anzeigen, bleiben sie blind für ihren Mangel an struktureller Autorität im KI-Ökosystem.

Diese Unternehmen haben ihre digitale Präsenz auf traditionellen SEO-Säulen aufgebaut: Content-Volumen, Backlink-Autorität, Keyword-Abdeckung und technischer Website-Zustand. Im Zeitalter der KI bilden diese Fundamente ein Fundament – aber kein Dach.
Die Suche belohnt Volumen und technische Ausführung. KI belohnt narrative Klarheit, Dominanz in der Kategorie und eine Konzentration von positivem Sentiment über ihre Trainingsquellen hinweg. Die beiden Kanäle sind einfach nicht so eng aufeinander abgestimmt, wie die meisten Marketingteams annehmen.
Extreme Diskrepanzen in drei Branchen
Das Missverhältnis zwischen Suchleistung und KI-Präsenz ist in drei Sektoren besonders ausgeprägt:
Aggregatoren und Vergleichsplattformen: Diese Plattformen, die als Vermittler zwischen Usern und Antworten dienen sollen, werden umgangen. KI eliminiert den Vermittler, indem sie die Anfrage direkt beantwortet. Diese Brands scheitern nicht an schlechter Umsetzung; der Kanal benötigt ihren Kernnutzen einfach nicht mehr.
E-Commerce in Mode und Einzelhandel: Während diese Brands massiven organischen Traffic über Produktlistenseiten und redaktionelle Inhalte generieren, blicken KI-Modelle bei der Formulierung von Antworten weitgehend an dieser Infrastruktur vorbei. Hohe Rankings in der Suche führen nicht mehr automatisch zu kategorialer Autorität in KI-Ökosystemen.
Versicherungen und Finanzdienstleistungen: Trotz hoher traditioneller Investitionen in Bildungsinhalte und Vergleichstools weisen alle großen Brands in diesen Sektoren ähnlich niedrige KI-Sichtbarkeits-Scores auf. Kein einziger Akteur hat es geschafft, seine klassischen organischen Investitionen erfolgreich in eine Differenzierung in der KI umzumünzen; die Modelle behandeln sie als völlig austauschbar.
Die strategische Implikation
Die Systeme, mit denen Sie Ihren Marketingerfolg messen, sind für einen Kanal optimiert, der vor einem strukturellen Niedergang steht. Das macht Sie blind für genau den Kanal, der ihn ersetzt.
Die nächste Grenze: Genauigkeit im großen Stil
Jedes Ergebnis dieser Analyse führt zu derselben unangenehmen Frage: Ihre Brand ist zwar in der KI-Antwort enthalten, aber ist die Antwort auch korrekt?
KI-Modelle halluzinieren häufig oder präsentieren selbstbewusst veraltete Fakten: falsche Preise, veraltete Produkte, die als aktuell dargestellt werden, Features, die dem falschen Modell zugeordnet werden, oder Marktaussagen, die seit achtzehn Monaten nicht mehr stimmen. Diese Ungenauigkeiten werden im großen Stil mit absoluter Autorität vorgebracht – oft ohne dass User Outbound-Links erhalten, um die Behauptungen zu überprüfen.
Während Sichtbarkeit und Sentiment mathematisch getrackt werden können, erfordert die Messung der Genauigkeit einen völlig anderen technischen Ansatz. Sie verlangt das Lesen des vollständigen Textes von KI-Antworten, das Identifizieren spezifischer faktischer Behauptungen und den Abgleich mit der verifizierten Wahrheit (Ground Truth).
Bei dem Volumen, mit dem KI arbeitet, ist ein manuelles Audit unmöglich. Es erfordert eine zweckgebundene Infrastruktur.
Das Volatilitätsrisiko
Die Brands, die diesem Risiko am stärksten ausgesetzt sind, sind nicht unbedingt diejenigen mit geringer Sichtbarkeit. Das höchste Risiko liegt bei Unternehmen in hochvolatilen Kategorien, in denen sich Produktspezifikationen, Compliance-Regeln und Preise schneller ändern als die Trainings- und Browsing-Zyklen der KI:
Finanzdienstleistungen
Unterhaltungselektronik
Reise und Tourismus
In diesen Sektoren ist eine selbstbewusste, verlinkungsfreie und veraltete KI-Antwort nicht mehr nur ein Marketing-Fehlschlag – sie ist ein Compliance- und Haftungsrisiko.
Die Lösung: Automatisiertes Fact-Checking
Wir bauen die Infrastruktur auf, um dieses Problem zu lösen. Automatisiertes Fact-Checking im KI-Maßstab – das systematische Auditieren der tatsächlichen Behauptungen, die KI-Modelle über Ihre Brand aufstellen, und das Markieren von Ungenauigkeiten, bevor sie sich potenzieren – startet bald auf der 3RD-Plattform.
Drei Metriken zur Modernisierung Ihrer Messung
Ihre bestehende Analytics-Infrastruktur ist nicht kaputt; sie misst lediglich die richtigen Dinge für eine Welt, die im Verschwinden begriffen ist.

Die folgenden drei Metriken sind kein Ersatz, sondern notwendige Erweiterungen, um Transparenz in Ihr aktuelles Reporting zu bringen.
Sichtbarkeit messen – nicht nur TrafficSind Sie Teil der KI-Unterhaltung und bei welchen Suchanfragen? Vermeiden Sie gemischte Sichtbarkeits-Scores. Fordern Sie stattdessen eine Aufschlüsselung auf Modellebene für bestimmte Abfragetypen an: Empfehlungen, Vergleiche und explorative Suchen. Für eine Brand in einem einzelnen Markt besteht der minimal sinnvolle Datensatz aus 40 bis 60 non-branded Prompts, die über 30 Tage hinweg konsistent ausgeführt werden.
Sentiment-Rate messen – nicht nur Mentions„Brand X ist eine von mehreren Optionen“ und „Brand X ist die bevorzugte Lösung“ stellen völlig unterschiedliche kommerzielle Ergebnisse dar. Tracken Sie das Verhältnis von positivem zu neutralem Sentiment bei Ihren KI-Erwähnungen. Eine Brand mit hoher Sichtbarkeit, aber überwiegend neutralem Sentiment ist zwar in der Konversation präsent, gewinnt sie aber nicht. Die Varianz von 19 % bis 95 % in unserem Datensatz beweist, wie viel kommerzielle Realität in einem einzigen Sichtbarkeits-Score verborgen liegt.
Genauigkeitsrisiko messen – nicht nur PräsenzÜberwachen Sie Ihre Erwähnungs- und Link-Raten nach Modell und Abfragetyp. Dort, wo Ihre Brand mit positivem Sentiment, aber ohne Outbound-Links erwähnt wird, ist Ihr Genauigkeitsrisiko am größten. Um dies abzumildern, optimieren Sie Ihr Schema-Markup: Strukturierte Daten liefern KI-Modellen präzise, eindeutige Daten und reduzieren die Angriffsfläche für selbstbewusste Fehler. Bei der Überwachung der Genauigkeit geht es nicht nur darum, Fehler zu vermeiden; es geht darum zu verifizieren, dass die „Ground Truth“ der KI mit Ihren offiziellen Markendaten übereinstimmt. Nur so lässt sich ein potenzielles Risiko in eine verifizierte Empfehlung verwandeln.
Die Gesamtrealität
Diese Metriken müssen zusammen bewertet werden. Eine hohe Sichtbarkeit gepaart mit einer niedrigen positiven Sentiment-Rate und einem hohen Genauigkeitsrisiko ist eine weitaus schlechtere strategische Position als eine geringere Sichtbarkeit mit einer hohen Sentiment-Rate und einem niedrigen Genauigkeitsrisiko. Die Kombination erzählt die Geschichte, die keine einzelne Metrik für sich allein darstellen kann.
Das Fazit
Das klassische Analytics-Dashboard lügt nicht durch eine Fehlfunktion. Es lügt systembedingt.
Es wurde entwickelt, um die Beweise von Einfluss in einer Welt zu tracken, in der Interaktionen klare digitale Fußabdrücke hinterließen: Sessions, Klicks, Pageviews und Conversions. Diese Welt ist nicht völlig verschwunden, aber Einfluss fließt zunehmend durch KI-generierte Umgebungen, die die Kaufabsicht prägen, Ihre Brand kontextualisieren und User Journeys umleiten – und das alles, ohne eine einzige Spur in Ihrem aktuellen Analytics-Stack zu hinterlassen.
Paradoxerweise sind die am stärksten gefährdeten Brands nicht diejenigen mit der geringsten KI-Sichtbarkeit. Das größte Risiko tragen die Marktführer mit der stärksten organischen Suchleistung. Dies sind die Unternehmen, die ihre gesamte Messinfrastruktur um genau den Kanal herum aufgebaut haben, den die KI still und heimlich verdrängt.
Da ihre klassischen Dashboards gesünder denn je aussehen, ist ihr blinder Fleck am größten.
Die Realität des modernen Marketings ist mittlerweile binär: Ihre Brand ist entweder in der KI-Antwort enthalten oder nicht. Und Sie können keinen blinden Fleck beheben, den Sie nicht messen wollen.
3RD ist eine KI-Sichtbarkeits-Intelligence-Plattform. Wir helfen Brands zu verstehen, wie sie über KI-Modelle hinweg dargestellt werden, zu identifizieren, wo ihre KI-Präsenz von ihrer beabsichtigten Positionierung abweicht, und die Metriken zu messen, auf die es in einer AI-First-Suchlandschaft ankommt.