The Searches You Never See: What ChatGPT Looks For Before It Names A Brand
We analysed 107.000 of ChatGPT's hidden fan-out queries across 31 brands on the 3RD platform. One source dominates the named searches, the same queries come back again and again, and reviews - not recency - are what it chases hardest.

When you ask ChatGPT "which bank is best for first-time buyers?" it does not search for that phrase. It quietly rewrites your question into several different searches - comparisons, reviews, specific competitors - runs them behind the scenes, and blends the results into one confident answer. Those hidden searches are called query fan-outs, and they are the layer where AI visibility is actually decided.
The problem is that almost nobody can see them. So we pulled ours. Across 31 brands the 3RD platform captured 50,872 ChatGPT responses that triggered fan-outs, producing 33,031 unique behind-the-scenes queries. Here is what they reveal.
50,872 ChatGPT responses with fan-outs | 107,000 distinct fan-out queries |
~20% of fan-outs go looking for reviews | 81% of search volume is repeat queries |
What The Fan-Outs Told Us
Reviews are the obsession. When ChatGPT names a review source it is overwhelmingly Trustpilot, and one in five fan-outs goes looking for reviews whether or not the user asked.
The same searches keep coming back. Most fan-out queries are one-offs, but a recurring core is re-issued so often that it accounts for 81% of all fan-out volume. Rank for those repeaters and you compound across every conversation.
Recency is real, but secondary. ChatGPT does reach for the current year when it searches, but review-seeking still outweighs freshness several times over.
Methodology and data source
We analysed the fan-out queries OpenAI models issued for 31 brands monitored on the 3RD platform: 50,872 responses that triggered fan-outs and 33,031 distinct behind-the-scenes queries.
Finding 1: The Obsession Is Reviews
When we tallied which named sources the LLM reaches for inside those searches, the result was not close. Trustpilot is the single most-named source in the whole corpus, dwarfing every other platform it points at by name.

Named sources ChatGPT searches (weighted occurrences). Counts only queries that name a source. Trustpilot is the one review platform that shows up consistently - more than 40x the next named source. A further ~11,000 review-seeking fan-outs name no platform at all, so this is the named-source picture, not the whole of review intent.
One in five of all fan-out queries goes looking for reviews. Most do not say where - but whenever ChatGPT does name a review platform, it is overwhelmingly Trustpilot. Either way the consequence is blunt: your Trustpilot profile is not a customer-service vanity metric. It is a primary input into how AI describes you - consulted before the model ever reads your own website.
ChatGPT consults Trustpilot before it consults you. Your rating is an AI ranking input, not a support metric.
And the other signals? Lower than you think
Strip the corpus down to the intent behind each search and a clear hierarchy emerges. Reviews lead. Price and comparison come next. Recency is present but secondary: current-year stamps land at roughly 4% of fan-outs - a genuine factor, but a small one next to reviews.

What ChatGPT injects into its hidden searches (share of fan-outs). The freshness figure shown is the genuine, corrected one.
ON RECENCY Recency is a genuine factor, not a myth. The current year (2025 and 2026 combined) appears in roughly 2,000 distinct fan-outs and about 3,500 searches - real, but a small share next to review-seeking, which is several times larger. We do exclude a separate older model that floods its searches with a stale "2024", because that is a model artifact rather than live freshness behaviour. |
Strip out the brand names and two words dominate
Take the brand names out of the fan-outs entirely and look at the generic vocabulary that is left. Two intents tower over everything: "best" and "reviews". Behind them sits a comparison frame - pros and cons, alternatives, providers - and a thin layer of commercial words like price and stores. ChatGPT is quietly reframing brand questions into "best [category]", review-seeking and head-to-head comparisons.
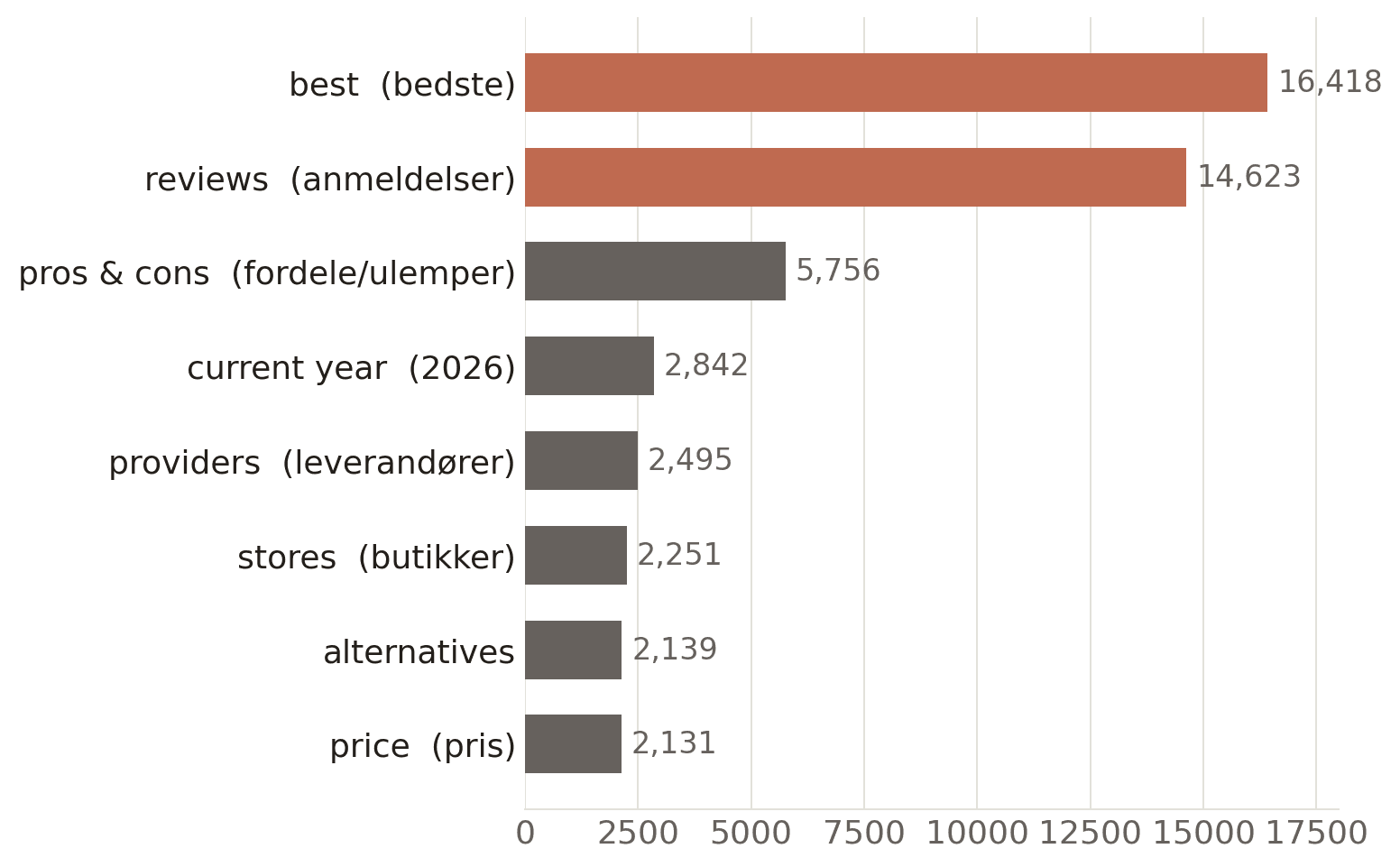
Most common unbranded words in the fan-outs (weighted, synonyms merged). Brand names, geography and search-template boilerplate removed; Danish and English synonyms merged (bedste/best, anmeldelser/reviews). The stale "2024" model artifact is excluded.
Finding 2: The Same Searches Keep Coming Back
The most strategically important pattern is not what ChatGPT searches for, but how often it searches for the same thing. Most fan-out queries are one-offs - but a recurring core is re-issued over and over, across many different prompts and runs. That core is small in count and enormous in weight.

Count of distinct fan-out queries, by how many times each was used. 62% are issued only once; the 38% that recur (orange) are re-fired far more often - the most-repeated single query was issued 80 times - which is why that minority drives the large majority of all fan-out volume.
38% of distinct fan-out queries are reused across two or more responses | 81% of all fan-out volume comes from that recurring core |
This is where leverage lives. A query the model keeps re-issuing - "[Competitor] Trustpilot anmeldelser", "compare the leading Danish providers of X" - is not a one-time event you can ignore. Earn a strong position on one of those repeaters and you are pulled into every future conversation that fans out to it. The recurring core, not the long tail of one-offs, is the target list.
A small set of searches drives most of the answers. Win the repeaters and you compound across every conversation.
What to do about it
The fan-out layer rewards a different playbook than classic SEO. Three moves follow directly from the data.
Treat reviews as an AI ranking input. Trustpilot is the review platform ChatGPT names most. Your rating, review volume and recency on the review platforms in your category shape the answer before your own site is ever read. Manage them like ranking factors, because that is what they are.
Answer the whole fan-out, not the literal prompt. One question becomes several searches covering best-of lists, reviews and comparisons. Content that only answers the exact phrasing misses most of the model's intent. Cover the angles, weave in review signals, and name the comparison set.
Win the repeaters. A small recurring core of sub-queries carries most of the volume. Identify the high-frequency fan-outs in your category - especially the brand-plus-reviews and "compare the leading X" patterns - and own them, because ranking for a repeater compounds.
The closing argument
Every AI answer about your brand is assembled from searches you cannot see, on sources you may not control. In our data those searches are dominated by two instincts - find the best option and find the reviews - and concentrated in a small set of queries the model fires again and again. Freshness is real but minor, and the raw volume of mentions tells you almost nothing about what the model actually went looking for.
Your brand is either inside that hidden layer or it is not. And you cannot optimise for a layer you refuse to measure.