LLM søgningerne du aldrig ser: Hvad ChatGPT leder efter, før den navngiver et brand
Vi analyserede 107.000 af ChatGPT's skjulte fan-out-søgninger på tværs af 31 brands på 3RD-platformen. Én kilde dominerer de navngivne søgninger, de samme søgninger vender tilbage igen og igen, og anmeldelser – ikke aktualitet – er det, den går mest efter.

Når du spørger ChatGPT "hvilken bank er bedst for førstegangskøbere?", søger den ikke efter den sætning. Den omskriver i al hemmelighed dit spørgsmål til flere forskellige søgninger - sammenligninger, anmeldelser, specifikke konkurrenter - kører dem bag kulisserne og blander resultaterne sammen til ét selvsikkert svar. Disse skjulte søgninger kaldes query fan-outs (søgningforgreninger), og de er det lag, hvor AI-synlighed rent faktisk bliver afgjort.
Problemet er, at næsten ingen kan se dem. Så vi trak vores data ud. Vores platform 3RD indsamlede på tværs af 31 brands, 50.872 ChatGPT-svar, der udløste fan-outs, hvilket genererede 33.031 unikke søgninger bag kulisserne. Her er, hvad de afslørerede.
50.872 ChatGPT-svar med fan-outs | 107.000 forskellige fan-out-søgninger |
~20% af fan-outs leder efter anmeldelser | 81% af søgevolumen er gentagne søgninger |
Hvad vores fan-outs fortalte os
Anmeldelser er besættelsen. Når ChatGPT nævner en kilde til anmeldelser, er det i overvældende grad Trustpilot, og én ud af fem fan-outs leder efter anmeldelser, uanset om brugeren spurgte efter det eller ej.
De samme søgninger vender hele tiden tilbage. De fleste fan-out-søgninger er engangsforekomster, men en tilbagevendende kerne gentages så ofte, at den står for 81% af al fan-out-volumen. Sørg for at rangere på disse gentagne søgninger, og du vil mærke effekten i hver eneste samtale.
Aktualitet er reel, men sekundær. ChatGPT leder ganske vist efter det aktuelle årstal, når den søger, men jagten på anmeldelser overskygger stadig friskhed flere gange.
Metode og datakilde
Vi analyserede de fan-out-søgninger, som OpenAIs modeller kørte for 31 brands, der overvåges på 3RD-platformen: 50.872 svar, der udløste fan-outs, og 33.031 unikke søgninger bag kulisserne.
Fund 1: Besættelsen af anmeldelser
Da vi talte op, hvilke navngivne kilder LLM'en rækker ud efter i disse søgninger, var resultatet ikke engang tæt. Trustpilot er den absolut mest navngivne kilde i hele datagrundlaget, og den overskygger enhver anden platform, den henviser til ved navn.

Navngivne kilder som ChatGPT søger efter (vægtede forekomster). Tæller kun søgninger, der nævner en kilde ved navn. Trustpilot er den eneste platform for anmeldelser, der dukker op konsekvent - mere end 40 gange så ofte som den næste navngivne kilde. Yderligere ~11.000 fan-outs på jagt efter anmeldelser nævner slet ingen platform, så dette er det navngivne billede, ikke hele billedet af folks intentioner om at finde anmeldelser.
Én ud af fem af alle fan-out-søgninger leder efter anmeldelser. De fleste uddyber ikke hvor - men hver gang ChatGPT rent faktisk nævner en anmeldelsesplatform, er det i overvældende grad Trustpilot. Uanset hvad er konsekvensen kontant: Din Trustpilot-profil er ikke bare et ligegyldigt tal for kundeservice. Det er et primært input til, hvordan AI beskriver dig - og det bliver tjekket, før modellen overhovedet læser din egen hjemmeside.
ChatGPT rådfører sig med Trustpilot, før den spørger dig. Din rating er et AI-rangeringsinput, ikke bare et serviceparameter.
Og de andre signaler? Lavere end du tror
Hvis vi skærer ind til benet og kigger på intentionen bag hver søgning, toner et klart hierarki frem. Anmeldelser fører an. Pris og sammenligning kommer bagefter. Aktualitet er til stede, men sekundær: det aktuelle årstal optræder i cirka 4% of alle fan-outs - en reel faktor, men lille sammenlignet med anmeldelser.

Hvad ChatGPT tilføjer i sine skjulte søgninger (andel af fan-outs). Friskhedstallet her er det reelle, korrigerede tal.
OM AKTUALITET Aktualitet er en reel faktor, ikke en myte. Det aktuelle år (2025 og 2026 kombineret) optræder i cirka 2.000 unikke fan-outs og omkring 3.500 søgninger - det er reelt, men en lille andel sammenlignet med jagten på anmeldelser, som er flere gange større. Vi har her udelukket en ældre model, der fylder sine søgninger med et forældet "2024", da det snarere er en systemfejl i modellen end et udtryk for aktiv søgen efter nyt indhold. |
Fjern brandnavne, og to ord dominerer fuldstændig
Tager man brandnavnene helt ud af de forskellige fan-outs og kigger på det generelle ordforråd, der er tilbage, tårner to hensigter sig op over alt andet: "bedste" og "anmeldelser". Bag dem ligger en sammenlignende ramme - fordele og ulemper, alternativer, udbydere - samt et tyndt lag af kommercielle ord som pris og butikker. ChatGPT omformulerer i al hemmelighed spørgsmål om specifikke brands til "bedste [kategori]", søgning efter anmeldelser og direkte sammenligninger.
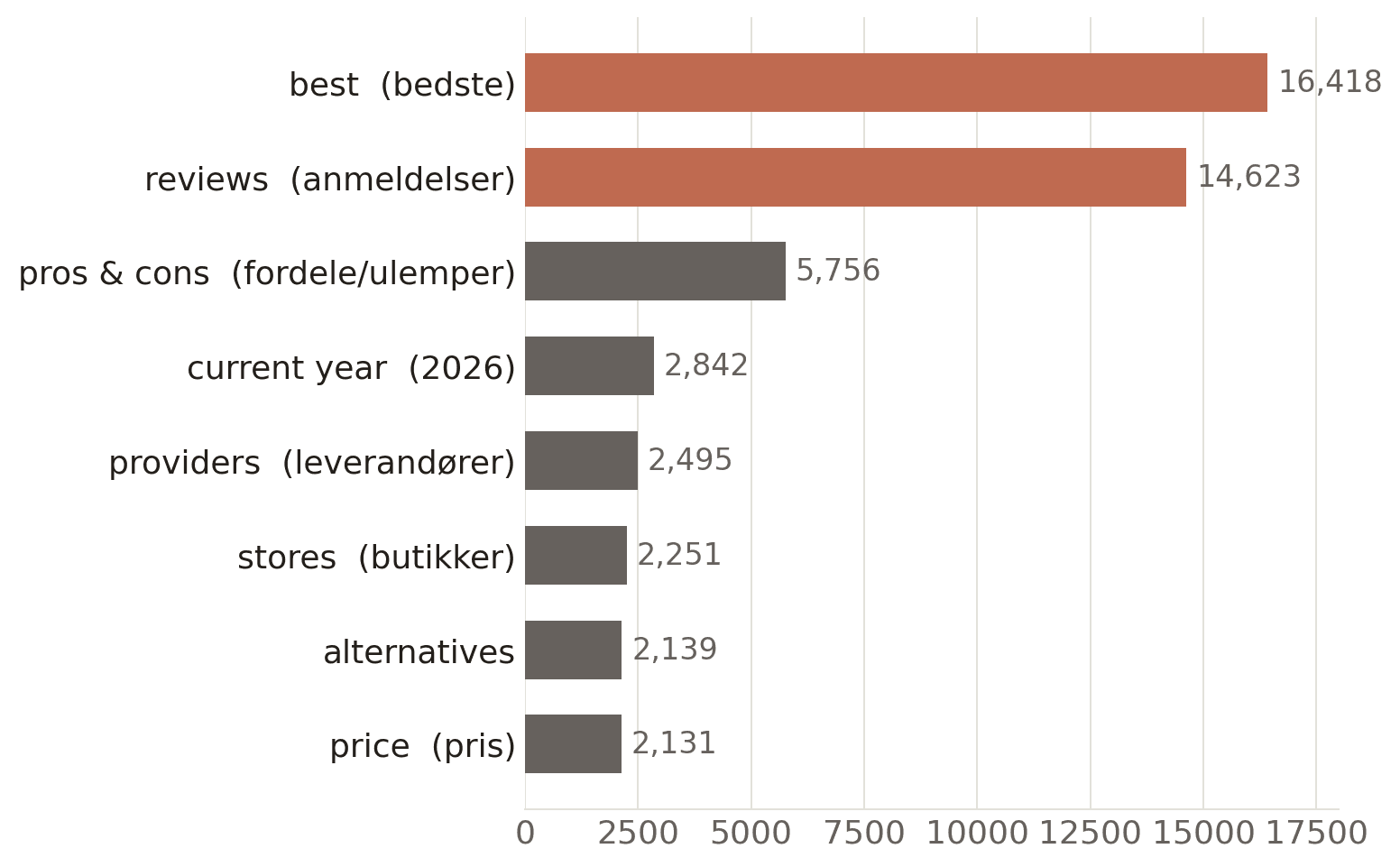
De mest almindelige ikke-brandede ord i vores fan-outs (vægtet, synonymer lagt sammen). Brandnavne, geografi og standardsætninger fra søgninger er fjernet; danske og engelske synonymer er lagt sammen (bedste/best, anmeldelser/reviews). Den forældede "2024"-modelmodel-fejl er udelukket.
Fund 2: De samme søgninger vender hele tiden tilbage
Det mest strategisk vigtige mønster er ikke, hvad ChatGPT søger efter, men hvor ofte den søger efter det samme. De fleste fan-out-søgninger sker kun en enkelt gang - men en fast kerne gentages igen og igen på tværs af mange forskellige prompts. Den kerne er lille i antal, men enorm i vægt.

Antallet af unikke fan-out-søgninger, fordelt på hvor mange gange de blev brugt. 62% bruges kun én gang; de 38%, der gentages (orange), bliver kørt langt oftere - den mest gentagne søgning blev kørt 80 gange - hvilket er grunden til, at det mindretal driver størstedelen af al fan-out-volumen.
38% af de unikke fan-out-søgninger genbruges på tværs af to eller flere svar | 81% af al fan-out-volumen kommer fra den tilbagevendende kerne |
Det er her, værdien ligger. En søgning, som modellen bliver ved med at køre - "[Konkurrent] Trustpilot anmeldelser", "sammenlign de førende danske udbydere af X" - er ikke en enlig svale, du kan ignorere. Får du en stærk placering på en af de gentagne søgninger, bliver du trukket ind i enhver fremtidig samtale, der forgrener sig til den. Den tilbagevendende kerne af søgninger, og ikke den lange hale af engangs-søgninger, er din vigtigste prioritering.
En lille række søgninger driver de fleste af svarene. Hvis du vinder på de gentagne søgninger, mærker du effekten i alle samtaler.
Hvad du skal gøre ved det
Fan-out-laget kræver en anden tilgang end klassisk SEO. Tre konkrete tiltag følger direkte af dataene.
Behandl anmeldelser som et AI-rangeringsinput. Trustpilot er den platform til anmeldelser, som ChatGPT oftest nævner. Din rating, mængden af anmeldelser og hvor nye de er på anmeldelsesplatformene i din kategori, definerer svaret, længe før din egen hjemmeside læses. Arbejd med dem som rangeringsfaktorer, for det er præcis, hvad de er.
Svar på hele søgeforgreningen, ikke kun det bogstavelige spørgsmål. Ét spørgsmål bliver til flere søgninger, der dækker over "bedste"-guides, anmeldelser og sammenligninger. Indhold, der kun svarer på den præcise formulering, misser det meste af modellens intention. Dæk de forskellige vinkler, tænk signaler fra anmeldelser ind, og nævn dine konkurrenter i sammenligningen.
Vind på de gentagne søgninger. En lille, fast kerne af undersøgninger trækker det meste af volumen. Identificer de hyppige fan-outs i din kategori - især mønstrene med brand-plus-anmeldelser og "sammenlign de førende X" - og ejer dem, da en god placering her hurtigt akkumulerer værdi.
Den afsluttende konklusion
Hvert eneste AI-svar om dit brand er stykket sammen af søgninger, du ikke kan se, på kilder, du måske ikke kontrollerer. I vores data er disse søgninger styret af to instinkter - find den bedste løsning og find anmeldelserne - og de er koncentreret om en lille gruppe søgninger, som modellen kører igen og igen. Friskhed er reel, men fylder minimalt, og den rene mængde af omtaler fortæller dig næsten intet om, hvad modellen reelt gik på jagt efter.
Dit brand er enten en del af det skjulte AI-lag, eller også er det ikke. Og du kan ikke optimere til et lag, du nægter at måle på.